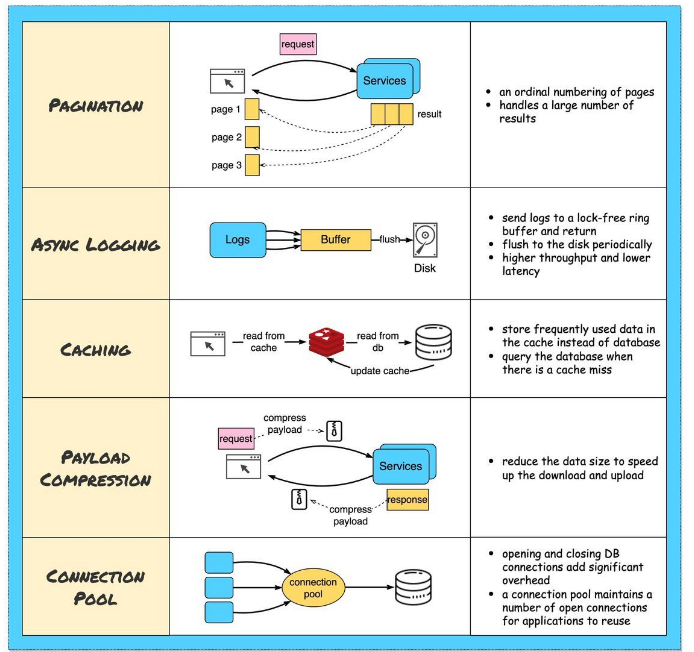
When fulfilling API requests, we often need to query the database. Opening a new connection for every API call adds overhead. Connection pooling helps avoid this penalty by reusing connections.
𝗛𝗼𝘄 𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻 𝗣𝗼𝗼𝗹𝗶𝗻𝗴 𝗪𝗼𝗿𝗸𝘀
1. For each API server, establish a pool of database connections at startup.
2. Workers share these connections, requesting one when needed and returning it after.
𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲𝘀 𝗳𝗼𝗿 𝗦𝗼𝗺𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀
However, setting up connection pooling can be more complex for languages like PHP, Python and Node.js. These languages handle scale by having multiple processes, each serving a subset of requests.
- In these languages, database connections get tied to each 𝗽𝗿𝗼𝗰𝗲𝘀𝘀.
- Connections can't be efficiently shared across processes. Each process needs its own pool, wasting resources.
In contrast, languages like Java and Go use threads within a single process to handle requests. Connections are bound at the application level, allowing easy sharing of a centralized pool.
𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻 𝗣𝗼𝗼𝗹𝗶𝗻𝗴 𝗦𝗼𝗹𝘂𝘁𝗶𝗼𝗻
Tools like PgBouncer work around these challenges by 𝗽𝗿𝗼𝘅𝘆𝗶𝗻𝗴 𝗰𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻𝘀 at the application level.
PgBouncer creates a centralized pool that all processes can access. No matter which process makes the request, PgBouncer efficiently handles the pooling.
At high scale, all languages can benefit from running PgBouncer on a dedicated server. Now the connection pool is shared over the network for all API servers. This conserves finite database connections.
Connection pooling improves efficiency, but its implementation complexity varies across languages.
Have you run into database connection limit issues as your API traffic grew? How did you troubleshoot and fix that?
𝗛𝗼𝘄 𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻 𝗣𝗼𝗼𝗹𝗶𝗻𝗴 𝗪𝗼𝗿𝗸𝘀
1. For each API server, establish a pool of database connections at startup.
2. Workers share these connections, requesting one when needed and returning it after.
𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲𝘀 𝗳𝗼𝗿 𝗦𝗼𝗺𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀
However, setting up connection pooling can be more complex for languages like PHP, Python and Node.js. These languages handle scale by having multiple processes, each serving a subset of requests.
- In these languages, database connections get tied to each 𝗽𝗿𝗼𝗰𝗲𝘀𝘀.
- Connections can't be efficiently shared across processes. Each process needs its own pool, wasting resources.
In contrast, languages like Java and Go use threads within a single process to handle requests. Connections are bound at the application level, allowing easy sharing of a centralized pool.
𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻 𝗣𝗼𝗼𝗹𝗶𝗻𝗴 𝗦𝗼𝗹𝘂𝘁𝗶𝗼𝗻
Tools like PgBouncer work around these challenges by 𝗽𝗿𝗼𝘅𝘆𝗶𝗻𝗴 𝗰𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝗼𝗻𝘀 at the application level.
PgBouncer creates a centralized pool that all processes can access. No matter which process makes the request, PgBouncer efficiently handles the pooling.
At high scale, all languages can benefit from running PgBouncer on a dedicated server. Now the connection pool is shared over the network for all API servers. This conserves finite database connections.
Connection pooling improves efficiency, but its implementation complexity varies across languages.
Have you run into database connection limit issues as your API traffic grew? How did you troubleshoot and fix that?
Improving API performance involves various strategies and techniques aimed at optimizing the speed, scalability, and efficiency of your API endpoints. Here are some key practices to consider:
1. **Use Caching**: Implement caching mechanisms such as HTTP caching (using cache-control headers) or server-side caching (using in-memory caches like Redis or Memcached) to store and serve frequently accessed data. Caching can significantly reduce response times for repeated requests.
2. **Optimize Database Queries**: Ensure that your database queries are optimized for performance. Use indexes, avoid unnecessary joins or subqueries, batch database operations, and consider database sharding or replication for scalability.
3. **Minimize Response Size**: Reduce the size of API responses by sending only the necessary data. Use pagination, selective field fetching (e.g., GraphQL), or compression techniques (e.g., gzip) to minimize the amount of data transferred over the network.
4. **Asynchronous Processing**: Offload long-running or resource-intensive tasks to background jobs or worker processes using asynchronous processing techniques. Use message queues (e.g., RabbitMQ, Kafka) or task queues (e.g., Celery) to handle asynchronous tasks.
5. **Optimize Network Calls**: Minimize the number of network calls and reduce latency by combining multiple API requests into batch requests (if supported by the API), using efficient protocols (e.g., HTTP/2), and optimizing network configurations (e.g., CDN, load balancing).
6. **Use Content Delivery Networks (CDNs)**: Utilize CDNs to cache and serve static assets (e.g., images, CSS, JavaScript) closer to end-users, reducing latency and improving overall API performance.
7. **Implement Rate Limiting**: Apply rate limiting to control the rate of incoming requests and prevent abuse or overload of your API endpoints. Rate limiting helps maintain system stability and ensures fair usage of resources.
8. **Monitor and Analyze Performance**: Use monitoring tools (e.g., Prometheus, Grafana, New Relic) to track API performance metrics such as response times, error rates, throughput, and resource utilization. Analyze performance data to identify bottlenecks and areas for optimization.
9. **Scale Horizontally**: If your API experiences high traffic or load, scale horizontally by adding more instances or replicas of your API servers. Container orchestration platforms like Kubernetes can help automate scaling based on demand.
10. **Continuous Optimization**: Continuously review and optimize your API code, infrastructure, and configurations based on performance metrics, user feedback, and evolving requirements. Regularly test API endpoints under load to identify and address performance issues proactively.
By implementing these best practices and continuously optimizing your API design, code, and infrastructure, you can achieve improved performance, reliability, and scalability for your API endpoints.
1. **Use Caching**: Implement caching mechanisms such as HTTP caching (using cache-control headers) or server-side caching (using in-memory caches like Redis or Memcached) to store and serve frequently accessed data. Caching can significantly reduce response times for repeated requests.
2. **Optimize Database Queries**: Ensure that your database queries are optimized for performance. Use indexes, avoid unnecessary joins or subqueries, batch database operations, and consider database sharding or replication for scalability.
3. **Minimize Response Size**: Reduce the size of API responses by sending only the necessary data. Use pagination, selective field fetching (e.g., GraphQL), or compression techniques (e.g., gzip) to minimize the amount of data transferred over the network.
4. **Asynchronous Processing**: Offload long-running or resource-intensive tasks to background jobs or worker processes using asynchronous processing techniques. Use message queues (e.g., RabbitMQ, Kafka) or task queues (e.g., Celery) to handle asynchronous tasks.
5. **Optimize Network Calls**: Minimize the number of network calls and reduce latency by combining multiple API requests into batch requests (if supported by the API), using efficient protocols (e.g., HTTP/2), and optimizing network configurations (e.g., CDN, load balancing).
6. **Use Content Delivery Networks (CDNs)**: Utilize CDNs to cache and serve static assets (e.g., images, CSS, JavaScript) closer to end-users, reducing latency and improving overall API performance.
7. **Implement Rate Limiting**: Apply rate limiting to control the rate of incoming requests and prevent abuse or overload of your API endpoints. Rate limiting helps maintain system stability and ensures fair usage of resources.
8. **Monitor and Analyze Performance**: Use monitoring tools (e.g., Prometheus, Grafana, New Relic) to track API performance metrics such as response times, error rates, throughput, and resource utilization. Analyze performance data to identify bottlenecks and areas for optimization.
9. **Scale Horizontally**: If your API experiences high traffic or load, scale horizontally by adding more instances or replicas of your API servers. Container orchestration platforms like Kubernetes can help automate scaling based on demand.
10. **Continuous Optimization**: Continuously review and optimize your API code, infrastructure, and configurations based on performance metrics, user feedback, and evolving requirements. Regularly test API endpoints under load to identify and address performance issues proactively.
By implementing these best practices and continuously optimizing your API design, code, and infrastructure, you can achieve improved performance, reliability, and scalability for your API endpoints.
No comments:
Post a Comment