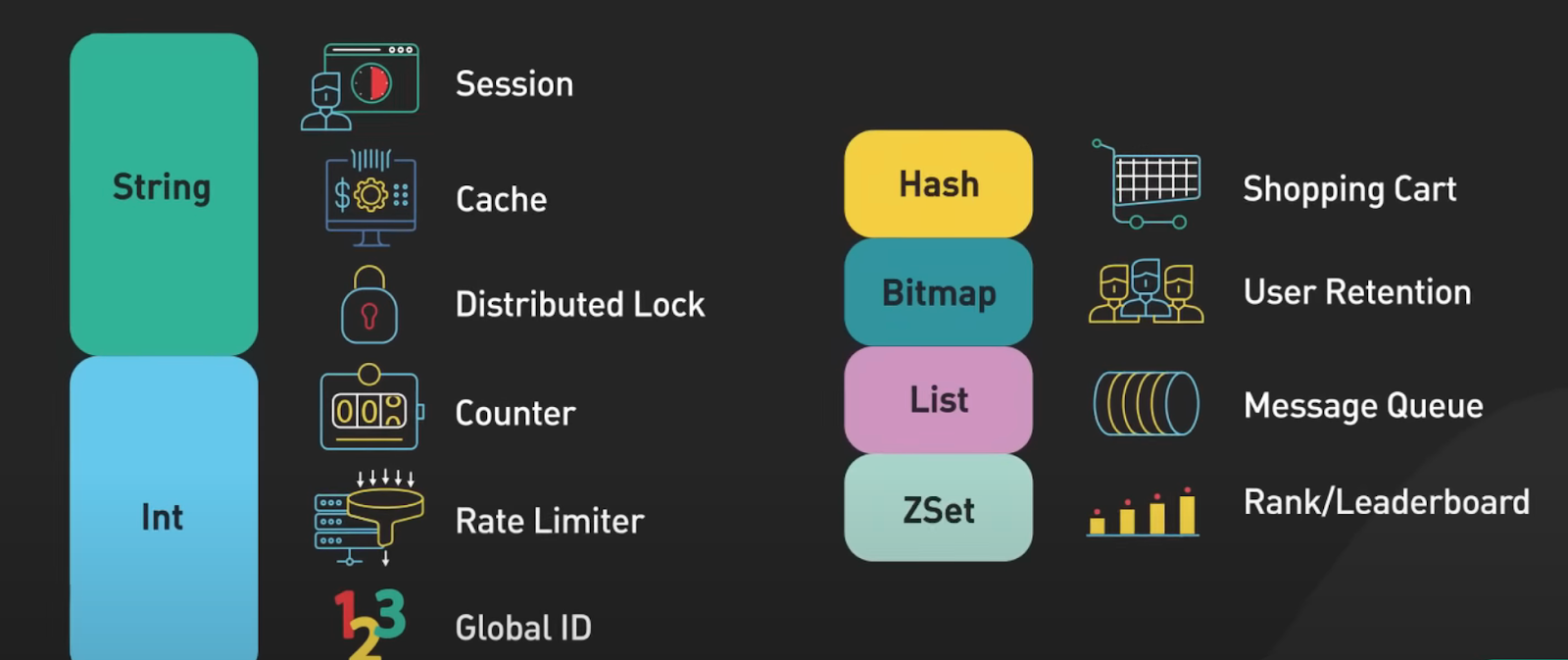
Redis is in-memory data structure store. It is most commonly used as cache. It supports many data structures like strings, hashes, lists, sets and sorted sets. Redis is known for its speed.
Primary use case of redis is caching objects to speed up web applications. Redis store frequently requested data in memory. It allows the web servers to return frequently accessed data quickly. This reduces the load on the database and improves the response time for the application. At scale, the cache is distributed among the cluster of redis servers. Sharding is the common technique to distribute the caching load evenly across the cluster. Other topics to consider while deploying redis as a distributed cache includes setting a correct TTL.
Another common use-case is to use as session store to share session data among stateless servers.When a user logs into a web application, a session data is stored in a Redis, along with a unique session ID that is return to the client as cookie. When a user makes a request to the application, the session ID is included in the the request, and the stateless web server retrieves the session data from REDIS using the ID.
It is important to note that Redis is in-memory database. The session data stored in Redis will be lost if the Redis server restarts. Even though Redis provide persistence options like snapshots and AOF (Append only file), that allow the session data to be stored in disk and reload in memory in the event of a restart, these options often take too long to load on restart to be practical. In production replication is usually used instead. In this case data is replicated to a backup instance, In the event of crash of the main instance, the backup is quickly promoted to take over to the traffic.
The next use case is Distributed Lock, used when multiple nodes in an application need to coordinate access to some shared resources. REdis is used as a distributed lock with its atomic commands like SETNX, or SET if not exists. It allows a caller to set a key only if already does not exist. eg Client1 tries to acquire the lock by setting a key with unique value and a timeout using the SETNX command.
Next is rate-limiter. Used as a rate-limiter by using its increment command on some counters and setting expiration timers on those counters. eg for every incoming request, the request IP or user ID is used as key. The number of request for the key is incremented using the INCR command in Redis,The current count is compared to the allowed rate limit. If the count is within the rate limit, the request is processed, if the count is over the limit, the request is rejected.The keys are set to expire after the specific time window eg a minute to reset the count for the next time window. Leaky bucket algorithm can also be used as rate limiter.
Last use case the game leaderboard, for most games that are not super high scale, redis is used. Sorted sets are the fundamentals data structure that enables this. A sorted set is the collection of the unique elements, each with a score associated with it. The elements are sorted by score. This allows for the quick retrieval of the elements by score in algorithmic time.
###
Redis is an open-source, in-memory data structure store that is used as a database, cache, and message broker. It is known for its high performance, scalability, and versatility, making it popular among developers for a wide range of use cases. Here are some key features and characteristics of Redis:
1. **In-Memory Data Store**: Redis stores data primarily in memory, which allows for extremely fast read and write operations. Data can be persisted to disk for durability, but the in-memory nature of Redis makes it ideal for caching frequently accessed data or temporary storage of transient data.
2. **Data Structures**: Redis supports a variety of data structures, including strings, hashes, lists, sets, sorted sets, bitmaps, and hyperloglogs. Each data structure is optimized for specific operations, such as adding, retrieving, updating, or deleting elements.
3. **Atomic Operations**: Redis provides atomic operations on its data structures, ensuring that operations are performed atomically and consistently. This makes Redis suitable for building distributed systems and implementing concurrency control mechanisms.
4. **Pub/Sub Messaging**: Redis supports publish/subscribe messaging, allowing clients to subscribe to channels and receive messages published to those channels. This feature enables real-time messaging, event-driven architectures, and message passing between different components of an application.
5. **Persistence**: Redis supports multiple persistence options, including snapshotting and append-only file (AOF) persistence. Snapshotting involves periodically saving a copy of the dataset to disk, while AOF persistence logs every write operation to a file, allowing for data recovery in case of system failures.
6. **Replication and High Availability**: Redis supports master-slave replication, where data is asynchronously replicated from a master node to one or more slave nodes. This provides data redundancy and high availability by allowing failover to a slave node in case the master node becomes unavailable.
7. **Clustering**: Redis Cluster is a distributed implementation of Redis that provides automatic sharding and partitioning of data across multiple nodes. This allows Redis to scale horizontally by distributing data and load across multiple instances.
8. **Lua Scripting**: Redis supports Lua scripting, allowing developers to write custom scripts that can be executed server-side. This enables complex data processing and manipulation operations to be performed within the Redis server itself.
9. **Client Libraries and APIs**: Redis provides client libraries and APIs for various programming languages, making it easy for developers to integrate Redis into their applications. These libraries provide convenient interfaces for interacting with Redis servers and performing operations on data structures.
Overall, Redis is a powerful and versatile data store that is widely used in modern web applications, real-time analytics, caching layers, messaging systems, and other use cases where high performance, scalability, and reliability are required. Its rich feature set and ease of use make it a popular choice among developers for building fast and scalable applications.
No comments:
Post a Comment