Linux boot process
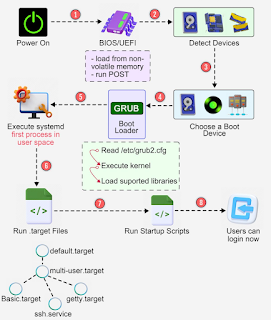
Linux Boot Process Illustrated
1. Power On: The computer loads either BIOS or UEFI.
2. Device Check: BIOS/UEFI identifies all connected hardware - including the processor (CPU), memory (RAM), and storage drives.
3. Boot Device Selection: The system picks which device to load the operating system.
4. Boot Loader: BIOS/UEFI starts GRUB (the boot loader), which shows a menu where you can:
- Choose which operating system to use
- Select special kernel options
5. Kernel to User Space: Once the Linux kernel is running, it launches systemd, which:
- Controls other programs and services
- Checks remaining hardware
- Sets up file systems
6. Default Target: systemd activates its default configuration and runs necessary system programs.
7. Login Ready: The system is now ready to use.
1. Power On: The computer loads either BIOS or UEFI.
2. Device Check: BIOS/UEFI identifies all connected hardware - including the processor (CPU), memory (RAM), and storage drives.
3. Boot Device Selection: The system picks which device to load the operating system.
4. Boot Loader: BIOS/UEFI starts GRUB (the boot loader), which shows a menu where you can:
- Choose which operating system to use
- Select special kernel options
5. Kernel to User Space: Once the Linux kernel is running, it launches systemd, which:
- Controls other programs and services
- Checks remaining hardware
- Sets up file systems
6. Default Target: systemd activates its default configuration and runs necessary system programs.
7. Login Ready: The system is now ready to use.
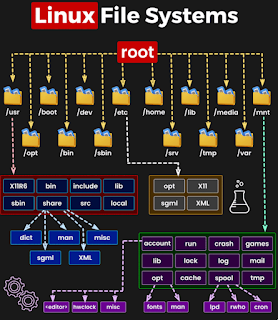
Everything in Linux stems from the root directory (/). Here's a breakdown of key directories:
1. /bin : Essential system binaries (bash, ls, grep)
2. /boot : Boot files (kernel, bootloader)
3. /dev : Device files
4. /etc : System configuration files
5. /home : User home directories
6. /lib : Shared libraries
7. /media : Removable media mount points
8. /mnt : Temporary filesystem mounts
9. /opt : Optional software packages
10. /proc : System and process information
11. /root : Root user's home
12. /sbin : System administration binaries
13. /srv : Service data storage
14. /tmp : Temporary files
15. /usr : User-installed software
16. /var : Variable data (logs, temp files)
Essential File System Commands:
• cd : Navigate directories
• ls : List contents
• mkdir : Create directory
• rmdir : Remove empty directory
• cp : Copy files/directories
• mv : Move/rename files/directories
• rm : Delete files/directories
⚠️ Pro Tip: Exercise caution when modifying system directories like /bin. Many are read-only for good reason!
1. /bin : Essential system binaries (bash, ls, grep)
2. /boot : Boot files (kernel, bootloader)
3. /dev : Device files
4. /etc : System configuration files
5. /home : User home directories
6. /lib : Shared libraries
7. /media : Removable media mount points
8. /mnt : Temporary filesystem mounts
9. /opt : Optional software packages
10. /proc : System and process information
11. /root : Root user's home
12. /sbin : System administration binaries
13. /srv : Service data storage
14. /tmp : Temporary files
15. /usr : User-installed software
16. /var : Variable data (logs, temp files)
Essential File System Commands:
• cd : Navigate directories
• ls : List contents
• mkdir : Create directory
• rmdir : Remove empty directory
• cp : Copy files/directories
• mv : Move/rename files/directories
• rm : Delete files/directories
⚠️ Pro Tip: Exercise caution when modifying system directories like /bin. Many are read-only for good reason!
What Is an Operating System
In simple terms, an operating system is a manager. It manages all the available resources on a computer. These resources can be the hard disk, a printer, or the monitor screen. Even memory is a resource that needs to be managed. Within an operating system are the management functions that determine who gets to read data from the hard disk, what file is going to be printed next, what characters appear on the screen, and how much memory a certain program gets.
Another function of the operating system is to keep track of what each program is doing. That is, the operating system needs to keep track of whose program, or task is currently writing its file to the printer or which program needs to read a certain spot on the hard disk, etc. This is the concept of multi-users, as multiple users have access to the same resources
Processes
One basic concept of an operating system is the process. If we think of the program as the file stored on the hard disk or floppy and the process as that program in memory.
A process is more than just a program. Especially in a multi-user, multi-tasking operating system such as UNIX, there is much more to consider. Each program has a set of data that it uses to do what it needs. Often, this data is not part of the program. For example, if you are using a text editor, the file you are editing is not part of the program on disk but is part of the process in memory. If someone else were to be using the same editor, both of you would be using the same program. However, each of you would have a different process in memory.programs are read from hard-disk to become a process.
With the exception of the init process (PID 1) every process is the child of another process. In general, every process has the potential to be the parent of another process. Perhaps the program is coded in such a way that it will never start another process. However, this is a limitation of that program and not the operating system. A process has only one parent but may have many children
The processors used by Linux (Intel 80386 and later, as well as the DEC Alpha, and SPARC) have built-in capabilities to manage both multiple users and multiple tasks
In addition to user processes, such as shells, text editors, and databases, there are system processes running. These are processes that were started by the system. Several of these deal with managing memory and scheduling turns on the CPU. Others deal with delivering mail, printing, and other tasks that we take for granted. In principle, both of these kinds of processes are identical. However, system processes can run at much higher priorities and therefore run more often than user processes.
Typically a system process of this kind is referred to as a daemon process or background process because they run behind the scenes (i.e. in the background) without user intervention. It is also possible for a user to put one of his or her processes in the background. This is done by using the ampersand (&) metacharacter at the end of the command line.
What normally happens when you enter a command is that the shell will wait for that command to finish before it accepts a new command. By putting a command in the background, the shell does not wait, but rather is ready immediately for the next command. If you wanted, you could put the next command in the background as well.
I have talked to customers who have complained about their systems grinding to a halt after they put dozens of processes in the background. The misconception is that because they didn't see the process running, it must not be taking up any resources. (Out of sight, out of mind.) The issue here is that even though the process is running in the background and you can't see it, it still behaves like any other process.
Virtual Memory Basics
One interesting aspect about modern operating systems is the fact that they can run programs that require more memory than the system actually has.
At the extreme end, this means that if your CPU is 32-bit (meaning that it has registers that are 32-bits), you can access up to 232 bytes (that 4,294,967,296 or 4 billion). That means you would need 4 Gb of main memory (RAM) in order to to completely take advantage of this.
The interesting thing is that when you sum the memory requirements of the programs you are running,you often reach far beyond the physical memory you have. Currently my system appears to need about 570 Mb. although my machine only has 384 Mb. Surprisingly enough I don't notice any performance problems. So, how is this possible?
From the user's perspective the email program (or parts of the word processor) are loaded into memory. However, the system only loads what it needs. In some cases, they might all be in memory at once. However, if you load enough programs, you eventually reach a point where you have more programs than you have memory.
To solve this problem, Linux uses something called "virtual memory". It's virtual because it can use more than you actually have. In fact, with virtual memory you can use the whole 232 bytes. Basically, what this means is that you can run more programs at once without the need for buying more memory
If you have more data than physical memory, the system might store it temporarily on the hard disk should it not be needed at the moment. The process of moving data to and from the hard disk like this is called swapping, as the data is "swapped" in and out. Typically, when you install the system, you define a specific partition as the swap partition, or swap "space". However, Linux can also swap to a physical file, although with older Linux versions this is much slower than a special partition. An old rule of thumb is that you have at least as much swap space as you do physical RAM, this ensures that all of the data can be swapped out, if necessary. You will also find that some texts say that you should have at least twice as much swap as physical RAM. We go into details on swap in the section in installing and upgrading.
Files and Directories
There are three kinds of files with which most people are familiar: programs, text files, and data files. However, on a UNIX system, there are other kinds of files. One of the most common is a device file. These are often referred to as device files or device nodes. Under UNIX, every device is treated as a file. Access is gained to the hardware by the operating system through the device files. These tell the system what specific device driver needs to be used to access the hardware.
Another kind of file is a pipe. Like a real pipe, stuff goes in one end and out the other. Some are named pipes. That is, they have a name and are located permanently on the hard disk. Others are temporary and are unnamed pipes. Although these do not exist once the process using them has ended, they do take up
physical space on the hard disk
Under Linux, a directory is actually nothing more than a file itself with a special format. It contains the names of the files associated with it and some pointers or other information to tell the system where the data for the file actually reside on the hard disk.
The directories have information that points to where the real files are.
One kind of file is a directory. What this kind of file can contain are files and more directories. These, in turn, can contain still more files and directories. The result is a hierarchical tree structure of directories, files, more directories, and more files. Directories that contain other directories are referred to as the parent directory of the child or subdirectory that they contain. (Most references I have seen refer only to parent and subdirectories. Rarely have I seen references to child directories.)
When referring to directories under UNIX, there is often either a leading or trailing slash ("/"), and sometimes both. The top of the directory tree is referred to with a single "/" and is called the "root" directory. Subdirectories are referred to by this slash followed by their name, such as /bin or /dev.
One thing to note is that John's business letter to Chris may be the exact same file as Jim's. I am not talking about one being a copy of the other. Rather, I am talking about a situation where both names point to the same physical locations on the hard disk. Because both files are referencing the same bits on the disk, they must therefore be the same file.
This is accomplished through the concept of a link. Like a chain link, a file link connects two pieces together. Take an example of "telephone number" for a file was its inode. This number actually points to a special place on the disk called the inode table, with the inode number being the offset into this table. Each entry in this table not only contains the file's physical location on this disk, but the owner of the file, the access permissions, and the number of links, as well as many other things. In the case where the two files are referencing the same entry in the inode table, these are referred to as hard links. A soft link or symbolic link is where a file is created that contains the path of the other file. We will get into the details of this later.
An inode does not contain the name of a file. The name is only contained within the directory. Therefore, it is possible to have multiple directory entries that have the same inode. Just as there can be multiple entries in the phone book, all with the same phone number. We'll get into a lot more detail about inodes in the section on filesystems. A directory and where the inodes point to on the hard disk might look like this
Let's think about the telephone book analogy once again. Although it is not common for an individual to have multiple listings, there might be two people with the same number. For example, if you were sharing a house with three of your friends, there might be only one telephone. However, each of you would have an entry in the phone book. I could get the same phone to ring by dialing the telephone number of four different people. I could also get the same inode with four different file names.
Under Linux, files and directories are grouped into units called filesystems. A filesystem is a portion of your hard disk that is administered as a single unit. Filesystems exist within a section of the hard disk called a partition. Each hard disk can be broken down into multiple partitions and the filesystem is created within the partition. Each has specific starting and ending points that are managed by the system. (Note: Some dialects of UNIX allow multiple filesystems within a partition.)
Operating System Layers
What accesses the hardware is a set of functions within the operating system itself (the kernel) called device drivers. If it does not behave correctly, a device driver has the potential of wiping out data on your hard disk or "crashing" your system. Because a device driver needs to be sure that it has properly completed its task (such as accurately writing or reading from the hard disk), it cannot quit until it has finished
Under Linux, there are many sets of programs that serve common functions. This includes things like mail or printing. These groups of related programs are referred to as "System Services", whereas individual programs such as vi or fdisk are referred to as utilities. Programs that perform a single function such as ls or date are typically referred to as commands.
The top-most directory is the root directory. In verbal conversation, you say "root directory" or "slash," whereas it may be referred to in text as simply "/."
The first directory we get to is /bin. Its name is derived from the word "binary." Often, the word "binary" is used to refer to executable programs or other files that contains non-readable characters. The /bin directory is where many of the system-related binaries are kept, hence the name. Although several of the files in this directory are used for administrative purposes and cannot be run by normal users, everyone has read permission on this directory, so you can at least see what the directory contains.
The /boot directory is used to boot the system. There are several files here that the system uses at different times during the boot process. For example, the files /boot/boot.???? are copies of the original boot sector from your hard disk. (for example boot.0300) Files ending in .b are "chain loaders," secondary loaders that the system uses to boot the various operating systems that you specify.
The /dev directory contains the device nodes. As I mentioned in our previous discussion on operating system basics, device files are the way both the operating system and users gain access to the hardware. Every device has at least one device file associated with it. If it doesn't, you can't gain access to it. We'll get into more detail on individual device files later.
The /etc directory contains files and programs that are used for system configuration. Its name comes from the common abbreviation etc., for etcetera, meaning "and so on." This seems to come from the fact that on many systems, /etc contains files that don't seem to fit elsewhere.
There several directories named /etc/cron*. As you might guess these are used by the cron daemon. The /etc/cron.d contains configuration files used by cron. Typically what is here are various system related cron jobs, such as /etc/cron.d/seccheck, which does various security checks. The directories /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, /etc/cron.monthly contain files with cron jobs which run hourly, daily, weekly and monthly, respectively. There is a cron job listed in /etc/crontab that runs the program /usr/lib/cron/run-crons, which checks the other files.
The /lib directory (for library) contains the libraries needed by the operating system as it is running. You will also find several sub directories.
The /usr directory contains many user-related subdirectories. Note the 'e' is missing from "user". In general, one can say that the directories and files under /usr are used by and related to users. There are programs and utilities here that users use on a daily basis. Unless changed on some systems, /usr is where users have their home directory. The figure below shows what the subdirectories of /usr would look like graphically.
Where /bin contains programs that are used by both users and administrators, /usr/bin contains files that are almost exclusively used by users. (However, like everything in UNIX, there are exceptions.) Here again, the bin directory contains binary files. In general, you can say the the programs and utilities that all user more or less require as stored in bin, whereas the "nice-to-have" programs and utilities are stored in /usr/bin. Programs and utilities needs for administrative tasks are stored in /sbin. Note that is common to seperate files like this, but it is not an absolute.
The /usr/src directory contains the source code for both the Linux kernel and for any program that you specifically install.
Many versions of Linux are now using the Red Hat Package Manager (RPM) format. In fact, RPM is perhaps the format most commonly found on the Internet. Most sites will have new or updated programs as RPM files. You can identify this format by the rpm extension to the file name.
This has proven itself to be a much more robust mechanism for adding and removing packages, as it is much easier to add and manage single programs than with Slackware. We'll get into more detail about this when I talk about installing. You will also find that RPM packages are also grouped into larger sets like those in Slackware, so the concepts are the same.
kill
By default, the kill command sends a termination signal to that process. Unfortunately, there are some cases where a process can ignore that termination signal. However, you can send a much more urgent "kill" signal like this:
kill -9
Where "9" is the number of the SIGKILL or kill signal. In general, you should first try to use signal 15 or SIGTERM. This sends a terminate singal and gives the process a chance to end "gracefully". You should also look to see if the process you want to stop has any children.
In some circumstances, it is not easy to kill processes by their PID. For example, if something starts dozens of other processes, it is ineffective to try to input all of their PIDs. To solve this problem Linux has the killall command and takes the command name instead of the PID. You can also use the -i, --interactive option to interactively ask you if the process should be kill or the -w, --wait option to wait for all killed processes to die. Note that if processed ignores the signal or if it is a zombie, then killall may end up waiting forever.
The Shell
As I mentioned in the section on introduction to operating systems, the shell is essentially a user's interface to the operating system. The shell is a command line interpreter, just like other operating systems. In Windows you open up a "command window" or "DOS box" to input commands, which is nothing other
than a command line interpreter. Through it, you issue commands that are interpreted by the system to carry out certain actions. Often, the state where the system is sitting at a prompt, waiting for you to type input, is referred to (among other things) as being at the shell prompt or at the command line.
The current directory is referenced by "." and its parent by ".." (often referred to in conversation as "dot" and "dot-dot").
Permissions
Permissions are set on a file using the chmod command or when the file is created (the details of which I will save for later). You can read the permissions on a file by using either the l command or ls -l. At the beginning of each line will be ten characters, which can either be dashes or letters. The first position is the type of the file, whether it is a regular file (-), a directory (d), a block device file (b), and so on. Below are some examples of the
various file types.
- - regular file
c - character device
b - block device
d - directory
p - named pipe
l - symbolic link
File and Directory Basics
Command Function
cd change directory
cp copy files
file determine a file's contents
ls list files or directories
ln make a link to a file
mkdir make a directory
mv move (rename) a file
rm remove a file
rmdir remove a directory
File Viewing
Command Function
cat Display the contents of file
less Page through files
head show the top portion of a file
more display screenfuls of a file
tail display bottom portion of a file
nl count the number of lines in a file
wc count the number of lines, words and characters in a file
od View a binary file
tee display output on stdout and write it to a file simultaneously
File Management
Command Function
ls display file attributes
stat display file attributes
wc count the number of lines, words and characters in a file
file identify file types
touch set the time stamp of a file or directory
chgrp change the group of a file
chmod change the permissions (mode) of a file
chown change the owner of a file
chattr change advanced file attributes
lsattr display advanced file attributes
File Manipulation
Command Function
awk pattern-matching, programming language
csplit split a file
cut display columns of a file
paste append columns in a file
dircmp compare two directories
find find files and directories
perl scripting language
sed Stream Editor
sort sort a file
tr translate chracters in a file
uniq find unique or repeated lines in a file
xargs process multiple arguements
File Editing
Command Function
vi text editor
emacs text editor
sed Stream Editor
Locate Files
Command Function
find find files and directories
which locate commands within your search path
whereis locate standard files
File Compression and Archiving
Command Function
gzip compress a file using GNU Zip
gunzip uncompress a file using GNU Zip
compress compress a file using UNIX compress
uncompress uncompress a file using UNIX compress
bzip2 compress a file using block-sorting file compressor
bunzip2 uncompress a file using block-sorting file compressor
zip compress a file using Windows/DOS zip
unzip uncompress a file using Windows/DOS zip
tar read/write (tape) archives
cpio copy files to and from archives
dump dump a disk to tape
restore restore a dump
mt tape control programm
File Comparison
Command Function
diff find differences in two files
cmp compare two files
comm compare sorted files
md5sum compute the MD5 checksum of a file
sum compute the checksum of a file
Disks and File Systems
Command Function
df display free space
du display disk usage
mount mount a filesystem
fsck check aand repair a filesystem
sync Flush disk caches
Printing
Command Function
lpr print files
lpq view the print queue
lprm Remove print jobs
lpc line printer control program
Process Management
Command Function
ps list processes
w list users' processes
uptime view the system load, amount of time it has been running, etc.
top monitor processes
free display free memory
kill send signals to processes
killall kill processes by name
nice set a processes nice value
renice set the nice value of a running process.
at run a job at a specific time
crontab schedule repeated jobs
batch run a job as the system load premits
watch run a programm at specific intervals
sleep wiat for a specified interval of time
Host Information
Command Function
uname Print system information
hostname Print the system's hostname
ifconfig Display or set network interface configuration
host lookup DNS information
nslookup lookup DNS information (deprecated)
whois Lookup domain registrants
ping Test reachability of a host
traceroute Display network path to a host
Networking Tools
Command Function
ssh Secure remote access
telnet Log into remote hosts
scp Securely copy files between hosts
ftp Copy files between hosts
wget Recursively download files from a remote host
lynx Character based web-browser
What is a process?
A process is a program in execution. The components of a process are: the program to be executed, the
data on which the program will execute, the resources required by the program—such as memory and file(s)—and the status of the execution.
Is a process the same as a program? No!, it is both more and less.
• more—a program is just part of a process context.
tar can be executed by two different people—same program (shared code) as part of different processes.
• less—a program may invoke several processes.cc invokes cpp, cc1, cc2, as, and ld.
Programming: uni- versus multi-
Some systems allow execution of only one process at a time (e.g., early personal computers).
They are called uniprogramming systems.
Others allow more than one process, i.e., concurrent execution of many processes. They are called multiprogramming (NOT multiprocessing!) systems.
In a multiprogramming system, the CPU switches automatically from process to process running each
for tens or hundreds of milliseconds. In reality, the CPU is actually running one and only one process at a time.
Process states
There are a number of states that can be attributed to a process: indeed, the operation of a multiprogramming system can be described by a state transition diagram on the process states. The states of a process include:
• New—a process being created but not yet included in the pool of executable processes (resource acquisition).
• Ready—processes that are prepared to execute when given the opportunity.
• Active—the process that is currently being executed by the CPU.
• Blocked—a process that cannot execute until some event occurs.
• Stopped—a special case of blocked where the process is suspended by the operator or the user.
• Exiting—a process that is about to be removed from the pool of executable processes (resource release).
Threads
Unit of execution (unit of dispatching) and a collection of resources, with which the unit of execution is associated, characterize the notion of a process.
A thread is the abstraction of a unit of execution. It is also referred to as a light-weight process (LWP) .
As a basic unit of CPU utilization, a thread consists of an instruction pointer (also referred to as the PC or
instruction counter), a CPU register set and a stack.A thread shares its code and data, as well as system
resources and other OS related information, with its peer group (other threads of the same process).
In simple terms, an operating system is a manager. It manages all the available resources on a computer. These resources can be the hard disk, a printer, or the monitor screen. Even memory is a resource that needs to be managed. Within an operating system are the management functions that determine who gets to read data from the hard disk, what file is going to be printed next, what characters appear on the screen, and how much memory a certain program gets.
Another function of the operating system is to keep track of what each program is doing. That is, the operating system needs to keep track of whose program, or task is currently writing its file to the printer or which program needs to read a certain spot on the hard disk, etc. This is the concept of multi-users, as multiple users have access to the same resources
Processes
One basic concept of an operating system is the process. If we think of the program as the file stored on the hard disk or floppy and the process as that program in memory.
A process is more than just a program. Especially in a multi-user, multi-tasking operating system such as UNIX, there is much more to consider. Each program has a set of data that it uses to do what it needs. Often, this data is not part of the program. For example, if you are using a text editor, the file you are editing is not part of the program on disk but is part of the process in memory. If someone else were to be using the same editor, both of you would be using the same program. However, each of you would have a different process in memory.programs are read from hard-disk to become a process.
With the exception of the init process (PID 1) every process is the child of another process. In general, every process has the potential to be the parent of another process. Perhaps the program is coded in such a way that it will never start another process. However, this is a limitation of that program and not the operating system. A process has only one parent but may have many children
The processors used by Linux (Intel 80386 and later, as well as the DEC Alpha, and SPARC) have built-in capabilities to manage both multiple users and multiple tasks
In addition to user processes, such as shells, text editors, and databases, there are system processes running. These are processes that were started by the system. Several of these deal with managing memory and scheduling turns on the CPU. Others deal with delivering mail, printing, and other tasks that we take for granted. In principle, both of these kinds of processes are identical. However, system processes can run at much higher priorities and therefore run more often than user processes.
Typically a system process of this kind is referred to as a daemon process or background process because they run behind the scenes (i.e. in the background) without user intervention. It is also possible for a user to put one of his or her processes in the background. This is done by using the ampersand (&) metacharacter at the end of the command line.
What normally happens when you enter a command is that the shell will wait for that command to finish before it accepts a new command. By putting a command in the background, the shell does not wait, but rather is ready immediately for the next command. If you wanted, you could put the next command in the background as well.
I have talked to customers who have complained about their systems grinding to a halt after they put dozens of processes in the background. The misconception is that because they didn't see the process running, it must not be taking up any resources. (Out of sight, out of mind.) The issue here is that even though the process is running in the background and you can't see it, it still behaves like any other process.
Virtual Memory Basics
One interesting aspect about modern operating systems is the fact that they can run programs that require more memory than the system actually has.
At the extreme end, this means that if your CPU is 32-bit (meaning that it has registers that are 32-bits), you can access up to 232 bytes (that 4,294,967,296 or 4 billion). That means you would need 4 Gb of main memory (RAM) in order to to completely take advantage of this.
The interesting thing is that when you sum the memory requirements of the programs you are running,you often reach far beyond the physical memory you have. Currently my system appears to need about 570 Mb. although my machine only has 384 Mb. Surprisingly enough I don't notice any performance problems. So, how is this possible?
From the user's perspective the email program (or parts of the word processor) are loaded into memory. However, the system only loads what it needs. In some cases, they might all be in memory at once. However, if you load enough programs, you eventually reach a point where you have more programs than you have memory.
To solve this problem, Linux uses something called "virtual memory". It's virtual because it can use more than you actually have. In fact, with virtual memory you can use the whole 232 bytes. Basically, what this means is that you can run more programs at once without the need for buying more memory
If you have more data than physical memory, the system might store it temporarily on the hard disk should it not be needed at the moment. The process of moving data to and from the hard disk like this is called swapping, as the data is "swapped" in and out. Typically, when you install the system, you define a specific partition as the swap partition, or swap "space". However, Linux can also swap to a physical file, although with older Linux versions this is much slower than a special partition. An old rule of thumb is that you have at least as much swap space as you do physical RAM, this ensures that all of the data can be swapped out, if necessary. You will also find that some texts say that you should have at least twice as much swap as physical RAM. We go into details on swap in the section in installing and upgrading.
Files and Directories
There are three kinds of files with which most people are familiar: programs, text files, and data files. However, on a UNIX system, there are other kinds of files. One of the most common is a device file. These are often referred to as device files or device nodes. Under UNIX, every device is treated as a file. Access is gained to the hardware by the operating system through the device files. These tell the system what specific device driver needs to be used to access the hardware.
Another kind of file is a pipe. Like a real pipe, stuff goes in one end and out the other. Some are named pipes. That is, they have a name and are located permanently on the hard disk. Others are temporary and are unnamed pipes. Although these do not exist once the process using them has ended, they do take up
physical space on the hard disk
Under Linux, a directory is actually nothing more than a file itself with a special format. It contains the names of the files associated with it and some pointers or other information to tell the system where the data for the file actually reside on the hard disk.
The directories have information that points to where the real files are.
One kind of file is a directory. What this kind of file can contain are files and more directories. These, in turn, can contain still more files and directories. The result is a hierarchical tree structure of directories, files, more directories, and more files. Directories that contain other directories are referred to as the parent directory of the child or subdirectory that they contain. (Most references I have seen refer only to parent and subdirectories. Rarely have I seen references to child directories.)
When referring to directories under UNIX, there is often either a leading or trailing slash ("/"), and sometimes both. The top of the directory tree is referred to with a single "/" and is called the "root" directory. Subdirectories are referred to by this slash followed by their name, such as /bin or /dev.
One thing to note is that John's business letter to Chris may be the exact same file as Jim's. I am not talking about one being a copy of the other. Rather, I am talking about a situation where both names point to the same physical locations on the hard disk. Because both files are referencing the same bits on the disk, they must therefore be the same file.
This is accomplished through the concept of a link. Like a chain link, a file link connects two pieces together. Take an example of "telephone number" for a file was its inode. This number actually points to a special place on the disk called the inode table, with the inode number being the offset into this table. Each entry in this table not only contains the file's physical location on this disk, but the owner of the file, the access permissions, and the number of links, as well as many other things. In the case where the two files are referencing the same entry in the inode table, these are referred to as hard links. A soft link or symbolic link is where a file is created that contains the path of the other file. We will get into the details of this later.
An inode does not contain the name of a file. The name is only contained within the directory. Therefore, it is possible to have multiple directory entries that have the same inode. Just as there can be multiple entries in the phone book, all with the same phone number. We'll get into a lot more detail about inodes in the section on filesystems. A directory and where the inodes point to on the hard disk might look like this
Let's think about the telephone book analogy once again. Although it is not common for an individual to have multiple listings, there might be two people with the same number. For example, if you were sharing a house with three of your friends, there might be only one telephone. However, each of you would have an entry in the phone book. I could get the same phone to ring by dialing the telephone number of four different people. I could also get the same inode with four different file names.
Under Linux, files and directories are grouped into units called filesystems. A filesystem is a portion of your hard disk that is administered as a single unit. Filesystems exist within a section of the hard disk called a partition. Each hard disk can be broken down into multiple partitions and the filesystem is created within the partition. Each has specific starting and ending points that are managed by the system. (Note: Some dialects of UNIX allow multiple filesystems within a partition.)
Operating System Layers
What accesses the hardware is a set of functions within the operating system itself (the kernel) called device drivers. If it does not behave correctly, a device driver has the potential of wiping out data on your hard disk or "crashing" your system. Because a device driver needs to be sure that it has properly completed its task (such as accurately writing or reading from the hard disk), it cannot quit until it has finished
Under Linux, there are many sets of programs that serve common functions. This includes things like mail or printing. These groups of related programs are referred to as "System Services", whereas individual programs such as vi or fdisk are referred to as utilities. Programs that perform a single function such as ls or date are typically referred to as commands.
The top-most directory is the root directory. In verbal conversation, you say "root directory" or "slash," whereas it may be referred to in text as simply "/."
The first directory we get to is /bin. Its name is derived from the word "binary." Often, the word "binary" is used to refer to executable programs or other files that contains non-readable characters. The /bin directory is where many of the system-related binaries are kept, hence the name. Although several of the files in this directory are used for administrative purposes and cannot be run by normal users, everyone has read permission on this directory, so you can at least see what the directory contains.
The /boot directory is used to boot the system. There are several files here that the system uses at different times during the boot process. For example, the files /boot/boot.???? are copies of the original boot sector from your hard disk. (for example boot.0300) Files ending in .b are "chain loaders," secondary loaders that the system uses to boot the various operating systems that you specify.
The /dev directory contains the device nodes. As I mentioned in our previous discussion on operating system basics, device files are the way both the operating system and users gain access to the hardware. Every device has at least one device file associated with it. If it doesn't, you can't gain access to it. We'll get into more detail on individual device files later.
The /etc directory contains files and programs that are used for system configuration. Its name comes from the common abbreviation etc., for etcetera, meaning "and so on." This seems to come from the fact that on many systems, /etc contains files that don't seem to fit elsewhere.
There several directories named /etc/cron*. As you might guess these are used by the cron daemon. The /etc/cron.d contains configuration files used by cron. Typically what is here are various system related cron jobs, such as /etc/cron.d/seccheck, which does various security checks. The directories /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly, /etc/cron.monthly contain files with cron jobs which run hourly, daily, weekly and monthly, respectively. There is a cron job listed in /etc/crontab that runs the program /usr/lib/cron/run-crons, which checks the other files.
The /lib directory (for library) contains the libraries needed by the operating system as it is running. You will also find several sub directories.
The /usr directory contains many user-related subdirectories. Note the 'e' is missing from "user". In general, one can say that the directories and files under /usr are used by and related to users. There are programs and utilities here that users use on a daily basis. Unless changed on some systems, /usr is where users have their home directory. The figure below shows what the subdirectories of /usr would look like graphically.
Where /bin contains programs that are used by both users and administrators, /usr/bin contains files that are almost exclusively used by users. (However, like everything in UNIX, there are exceptions.) Here again, the bin directory contains binary files. In general, you can say the the programs and utilities that all user more or less require as stored in bin, whereas the "nice-to-have" programs and utilities are stored in /usr/bin. Programs and utilities needs for administrative tasks are stored in /sbin. Note that is common to seperate files like this, but it is not an absolute.
The /usr/src directory contains the source code for both the Linux kernel and for any program that you specifically install.
Many versions of Linux are now using the Red Hat Package Manager (RPM) format. In fact, RPM is perhaps the format most commonly found on the Internet. Most sites will have new or updated programs as RPM files. You can identify this format by the rpm extension to the file name.
This has proven itself to be a much more robust mechanism for adding and removing packages, as it is much easier to add and manage single programs than with Slackware. We'll get into more detail about this when I talk about installing. You will also find that RPM packages are also grouped into larger sets like those in Slackware, so the concepts are the same.
kill
By default, the kill command sends a termination signal to that process. Unfortunately, there are some cases where a process can ignore that termination signal. However, you can send a much more urgent "kill" signal like this:
kill -9
Where "9" is the number of the SIGKILL or kill signal. In general, you should first try to use signal 15 or SIGTERM. This sends a terminate singal and gives the process a chance to end "gracefully". You should also look to see if the process you want to stop has any children.
In some circumstances, it is not easy to kill processes by their PID. For example, if something starts dozens of other processes, it is ineffective to try to input all of their PIDs. To solve this problem Linux has the killall command and takes the command name instead of the PID. You can also use the -i, --interactive option to interactively ask you if the process should be kill or the -w, --wait option to wait for all killed processes to die. Note that if processed ignores the signal or if it is a zombie, then killall may end up waiting forever.
The Shell
As I mentioned in the section on introduction to operating systems, the shell is essentially a user's interface to the operating system. The shell is a command line interpreter, just like other operating systems. In Windows you open up a "command window" or "DOS box" to input commands, which is nothing other
than a command line interpreter. Through it, you issue commands that are interpreted by the system to carry out certain actions. Often, the state where the system is sitting at a prompt, waiting for you to type input, is referred to (among other things) as being at the shell prompt or at the command line.
The current directory is referenced by "." and its parent by ".." (often referred to in conversation as "dot" and "dot-dot").
Permissions
Permissions are set on a file using the chmod command or when the file is created (the details of which I will save for later). You can read the permissions on a file by using either the l command or ls -l. At the beginning of each line will be ten characters, which can either be dashes or letters. The first position is the type of the file, whether it is a regular file (-), a directory (d), a block device file (b), and so on. Below are some examples of the
various file types.
- - regular file
c - character device
b - block device
d - directory
p - named pipe
l - symbolic link
File and Directory Basics
Command Function
cd change directory
cp copy files
file determine a file's contents
ls list files or directories
ln make a link to a file
mkdir make a directory
mv move (rename) a file
rm remove a file
rmdir remove a directory
File Viewing
Command Function
cat Display the contents of file
less Page through files
head show the top portion of a file
more display screenfuls of a file
tail display bottom portion of a file
nl count the number of lines in a file
wc count the number of lines, words and characters in a file
od View a binary file
tee display output on stdout and write it to a file simultaneously
File Management
Command Function
ls display file attributes
stat display file attributes
wc count the number of lines, words and characters in a file
file identify file types
touch set the time stamp of a file or directory
chgrp change the group of a file
chmod change the permissions (mode) of a file
chown change the owner of a file
chattr change advanced file attributes
lsattr display advanced file attributes
File Manipulation
Command Function
awk pattern-matching, programming language
csplit split a file
cut display columns of a file
paste append columns in a file
dircmp compare two directories
find find files and directories
perl scripting language
sed Stream Editor
sort sort a file
tr translate chracters in a file
uniq find unique or repeated lines in a file
xargs process multiple arguements
File Editing
Command Function
vi text editor
emacs text editor
sed Stream Editor
Locate Files
Command Function
find find files and directories
which locate commands within your search path
whereis locate standard files
File Compression and Archiving
Command Function
gzip compress a file using GNU Zip
gunzip uncompress a file using GNU Zip
compress compress a file using UNIX compress
uncompress uncompress a file using UNIX compress
bzip2 compress a file using block-sorting file compressor
bunzip2 uncompress a file using block-sorting file compressor
zip compress a file using Windows/DOS zip
unzip uncompress a file using Windows/DOS zip
tar read/write (tape) archives
cpio copy files to and from archives
dump dump a disk to tape
restore restore a dump
mt tape control programm
File Comparison
Command Function
diff find differences in two files
cmp compare two files
comm compare sorted files
md5sum compute the MD5 checksum of a file
sum compute the checksum of a file
Disks and File Systems
Command Function
df display free space
du display disk usage
mount mount a filesystem
fsck check aand repair a filesystem
sync Flush disk caches
Printing
Command Function
lpr print files
lpq view the print queue
lprm Remove print jobs
lpc line printer control program
Process Management
Command Function
ps list processes
w list users' processes
uptime view the system load, amount of time it has been running, etc.
top monitor processes
free display free memory
kill send signals to processes
killall kill processes by name
nice set a processes nice value
renice set the nice value of a running process.
at run a job at a specific time
crontab schedule repeated jobs
batch run a job as the system load premits
watch run a programm at specific intervals
sleep wiat for a specified interval of time
Host Information
Command Function
uname Print system information
hostname Print the system's hostname
ifconfig Display or set network interface configuration
host lookup DNS information
nslookup lookup DNS information (deprecated)
whois Lookup domain registrants
ping Test reachability of a host
traceroute Display network path to a host
Networking Tools
Command Function
ssh Secure remote access
telnet Log into remote hosts
scp Securely copy files between hosts
ftp Copy files between hosts
wget Recursively download files from a remote host
lynx Character based web-browser
What is a process?
A process is a program in execution. The components of a process are: the program to be executed, the
data on which the program will execute, the resources required by the program—such as memory and file(s)—and the status of the execution.
Is a process the same as a program? No!, it is both more and less.
• more—a program is just part of a process context.
tar can be executed by two different people—same program (shared code) as part of different processes.
• less—a program may invoke several processes.cc invokes cpp, cc1, cc2, as, and ld.
Programming: uni- versus multi-
Some systems allow execution of only one process at a time (e.g., early personal computers).
They are called uniprogramming systems.
Others allow more than one process, i.e., concurrent execution of many processes. They are called multiprogramming (NOT multiprocessing!) systems.
In a multiprogramming system, the CPU switches automatically from process to process running each
for tens or hundreds of milliseconds. In reality, the CPU is actually running one and only one process at a time.
Process states
There are a number of states that can be attributed to a process: indeed, the operation of a multiprogramming system can be described by a state transition diagram on the process states. The states of a process include:
• New—a process being created but not yet included in the pool of executable processes (resource acquisition).
• Ready—processes that are prepared to execute when given the opportunity.
• Active—the process that is currently being executed by the CPU.
• Blocked—a process that cannot execute until some event occurs.
• Stopped—a special case of blocked where the process is suspended by the operator or the user.
• Exiting—a process that is about to be removed from the pool of executable processes (resource release).
Threads
Unit of execution (unit of dispatching) and a collection of resources, with which the unit of execution is associated, characterize the notion of a process.
A thread is the abstraction of a unit of execution. It is also referred to as a light-weight process (LWP) .
As a basic unit of CPU utilization, a thread consists of an instruction pointer (also referred to as the PC or
instruction counter), a CPU register set and a stack.A thread shares its code and data, as well as system
resources and other OS related information, with its peer group (other threads of the same process).
No comments:
Post a Comment