BGP Overview
============
Open Standards based
-RFC 4271 “ A border gateway protocol 4 (BGP-4)”
Classless path vector routing protocol
-uses multiple “attributes” for routing decision
-supports VLSM and summarization
-Extensible
IPV4 Multicast, IPv6, MPLS, etc.
BGP ASNs
=============
Autonomous Systems (AS)
-a set of routers under a single technical administration, using an interior gateway protocol(IGP) and common metrics to determine how to route packets within the AS, and using an inter-AS routing protocol to determine how to route packets to other Ases.
ASNs are allocated by Internet assigned number authority (IANA)
Generally, BGP relies on ospf, ISIS, Eigrp to advertise routing within AS.
BGP ASN Values
================
Originally 2 byte field
-value 0-65535
-public ASNs 1-64511
-private ASNs 64512-65535
Now 2 byte is already occupied so we come up with 4 byte AS
Currently 4-byte field
-BGP support for four-octet AS number space
4-Byte BGP ASN
==============
0.0 – 65535.65535 notation
-0.[0-65535] denote original 2 byte ASNs
Requires backwards compatibility with old code.
-4 byte ASN support negotiated during capability exchange
-old bgp speakers are sent ASdot numbers encoded as ASN “23456”
-real AS-Path encoded with optional transitive attributes AS4_AGGREGATOR and AS4_PATH
Establishing BGP Peerings
=====================
Like IGP, the first step in BGP is to find neighbors to exchange information with
Unlike IGP..
-BGP does not have its own transport
-BGP has different types of neighbors
-BGP neighbors are not discovered
-BGP neighbors do not have to be connected
Since we have a TCP used as a L4 protocol(logical) for the establishment, hence neighbors in case of IBGP need not to be directly connected.
BGP Transport
================
BGP uses TCP port 179 for transport
-Implies that BGP needs IGP first
BGP neighbor statements tells process to
-listen for remote address via TCP 179
-initiate a session to remote address via TCP 179
-If collision, higher router-id becomes TCP client
Note: if you want to use BGP only then there should be a physical connection between all routers ie full mesh which has again routing issues. Hence we use IGP within IBGP for route recursion process to BGP next hop value.
BGP Peering Types
===============
External BGP (EBGP ) peers
-neighbors outside my AS
Internal BGP(iBGP) Peers
-neighbors inside my AS
Update and pacth selection rules change depending on what type of peer a route is being sent to/received from
BGP Peering Rules
===========
EBGP packets default to TTL 1
-Can be modified if neighbors are multiple hops away
.neighbor ebgp-multihop [ttl]
.neighbor ttl-security hops [ttl]
Nom multi-hop peers must be directly connected by default
-can be modified if connected neighbors peer via Loopbacks
.neighbor disable –connected-check
Loop prevention via AS-PATH
-Local ASN is prepended to outbound updates
-Inbound updates containing local ASN are discarded
-can be modified with neighbor allows-in
Next-hop processing
-outbound EBGP updates have local update-source for neighbor set as next-hop
Eg. If update-source is Loopback0, next –hop is loopback0
-Can be modified with route-map action set ip next-hop but typically shouldn’t
.eg third-party next-hop
Note: control plane = session = routing update
Data plane = data forwarding = actual data flow.
IBGP packets default to TTL 255
-implies neighbors do not have to be connected as long as IGP reachability exists
Loop prevention via route filtering
-iBGP learned routes cannot be advertised on to another IBGP neighbor
-Implies need for either..
.fully meshed iBGP peerings
.router reflection
.confederation
Next-hop Processing
===================
-Outbound iBGP updates do not modify the next-hop attribute regardless of IBGP peer type
.iBGP peer
.Route reflector’s client peer
.Route Reflector’s non-client peer
.Confederation EBGP peer
-Can be modified with neighbor next-hop-self on route-map action set ip next-hop
Note : in case of BGp control and data plane are disconnected which gives us a flexibility to route outbound traffic based on route-map.
BGP Transport
==============
TCP server must agree on where client’s session is coming from
-if server does not expect session it will refuse
Client’s packet is sourced from outgoing interface in the routing table.
-can be modified with update-source per neighbor
iBGP Route reflection
======================
Eliminates need of full mesh
-only need peering(s) to the RR(s)
Like OSPF DR & IS-IS DIS, minimizes prefix replication
-send one update to the RR
-RR sens the update to its “clients”
Loop prevention through Cluster-ID
-RR discards routed received with its own cluster-id
-does not modify other attributes such as next-hop
Route reflector Peerings
===================
Route reflector can have three types of peers
-EBGP peers
.neighbors in differnet AS
-Client peers
.IBGP peers with route-reflector-client
-Non-client peers
.IBGP peers without route-reflector-client
Route Reflector Update Processing
======================
RR processes update differently depending on what type of peer they came from
-EBGP learned routes
.can be advertised to EBGP peers, clients, & Non clients
-client learned routes
.can be advertised to EBGP peers, clients, & non clients
-Non-cleient learned routes
.can be advertised to EBGP peers and clients
RR placement based upon these rules
Large Scale Route Reflection
=========================
Larger scale BGP designs cannot be serviced by only a single RR
-single RR is a single point of failure
RR “clusters” allow redundancy and hierarchy
-cluster is defined by the clients a RR servers
-RRs in the same cluster use the same cluster-ID
Inter-Cluster peerings between RRs can be client or non-client peerings
-depends on redundancy design
BGP Confederation
+=================
Reduces full mesh IBGP requirement by splitting AS into smaller Sub-Ases
-inside Sub-AS full mesh or RR requirement remains
-between sub-AS acts like EBGP
Devices outside the confederation do not know about the internal structure
-Sub-AS numbers are stripped from advertisements to “true” EBGP peers
Typically uses ASNs in private range (64512-65635)
BGP Confederation Configuration
=====================
Enable the BGP process
-router bgp [sub-as]
Specify the main AS number
-bgp confederation-id [main-as]
Specify other Sub-Ases that you peer with
-bgp confederation-peers [sub-as1 sub-asn]
-Not all sub-Ases, just those directly peered with
BGP NLRI Advertisement
====================
BGP NLRI can be originated by
-network statement
.requires exact match in the routing table first
-redistribute statement
.won’t include OSPF External by default
-aggregate-address statement
.requires one subnet in BGP table first
-bgp inject-map statement
.opposite of aggregation
BGP Network Statement
=====================
Originates prefixes with ORIGIN of iGP(i)
Requires exact match in the routing table
-Does not have to be a connected prefix, can be learned via IGP
Without mask keyword assumes classful mask
BGP redistribute statement
=======================
Originates prefixes with ORIGIN of INCOMPLETE (?)
Originates classfull summary if auto-summary is enabled
Automatically copies IGP metric to BGP MED
Won’t include OSPF external by default
-redistribute ospf [pid] match internal external
BGP Aggregation
=================
Can be applied at any point in the network as long as one subnet is in the bGP table
Configured as aggregate-address [network] [mask] [args]
Arguments are ..
-summary-only
-suppress-map
-attribute-map | route-map
-as-set
-advertise-map
BGP conditional Route Injection
======================
Originates subnest(s) from aggregate for purpose of longest match traffic engineering
Configured as bgp inject-map inject-map exist-map exist-map [copy-attributes]
-Inject Map
.subnet to be advertised
.set ip address prefix-list [list]
-Exist Map
.Aggreate to be originated from
.match ip address prefix-list [list]
.match ip route-source prefix-list [list]
BGP Best Path Selection
===================
Chooses which routes can be
-installed in the RIB/FIB
-Advertised to the other BGP peers
Best path selection prerequisites
============================
Nexthop value must be in the routing table
-prevents route-recursion failure
Synchronization rule must be met or disabled
-Legacy black-hole prevention technique
AS-Path must not contain local-AS
-Normal EBGP loop prevention
First ASN in path must be neighbor’s ASN
-bgp enforce-first-as command
Best path Selection Order
====================
Weight
Local Preference
Locally Originated
AS-Path
Origin
MED
EBGP over IBGP (This is different form the AD)
IGP metric to Next-hop
Tie breakers
-Oldest
-Lowest RID
-Shortest cluster list
-Lowest neighbor address
Manipulating Best path selection
==========================
Outbound routing policy affects inbound traffic
Inbound routing policy affects outbound traffic
Weight and local pref
-set inbound
-affects outbound traffic
AS-path and MED
-set outbound
-affects inbound traffic
Best Path Selection Exception
=========================
AS-Path
-bgp bestpath as-path ignore
MED
-bgp always-compare-med
-bgp bestpath med-confed
.compare med for routes locally originated in the confederation
-bgp bestpath med missing-as-worst
.assign MED of 4,294,967,294 to NULL MED
-bgp deterministic med
.compare MED against all possible paths
BGP Communities
================
BGP’s implementation of a route-tag
Used to group prefixes together for
-advertisement policy
-filtering policy
-best path selection policy
Community is an optional transitive attribute
-not exchanged between peers by default
-neighbor [address] send-community
BGP Community Values
==============
Standard community is 4-byte value
Can be denoted as ..
-decimal (0-42944967296)
-AA:NN(00: - 65635:65535)
.ip bgpcommunity new-format
-same binary value regardless of visual format
Three “well-known” values are reserved
BGP well-known communities
=======================
No-export (0xFFFFFF01)
-don’t advertise to EBGP peers
No-advertise (0xFFFFFF02)
-don’t advertise to any peers
Local-AS (0xFFFFFF03)
-don’t advertise to confederation EBGP peers
-RFC defines as NO_EXPORT_SUBCONFED
Matching and setting Communities
==========================
Set occurs in route-map
-set community {community-number [additive] [well-known-community] | none}
-not additive by default
Match occurs by community-list
-Define list
.standard list matches community name or number
-ip community-list 1 standard permit no-export
.expanded matches regular expression
-ip community-list expanded AS100 permit 100:[0-9]+
-Reference from route-map
.match community AS100
Regular Expressions
=================
Used for string matching in..
-show command outputs
-TCL/EEM scripting
-BGP AS-path access lists
-BGP Expanded community lists
BGP Filtering
=================
BGP updates filtering occurs on a per peer bassis with..
-neighbor [address] distribute-list
-neighbor [address] filter-list
-neighbor [address] prefix-list
-neighbor [address] route-map
Using route-map avoids order of operations issues.
BGP Convergence
================
Hello and keepalive timers
-lowest timers are negotiated during peering establishment
-timers bgp
-neighbor timers
Link down detection
-bgp fast-external-fallover
Update timers
.neighbor advertisement-interval
-bgp nexthop {trigger {delay seconds | enable} | route-map map-name}
-bgp scan-time
-bgp update-delay
BGP Default routing
==================
Three ways to originate default
-default-information originate + redistribute
-network 0.0.0.0 mask 0.0.0.0
-neighbor default-originate
.supports conditional advertisement
Miscellaneous :
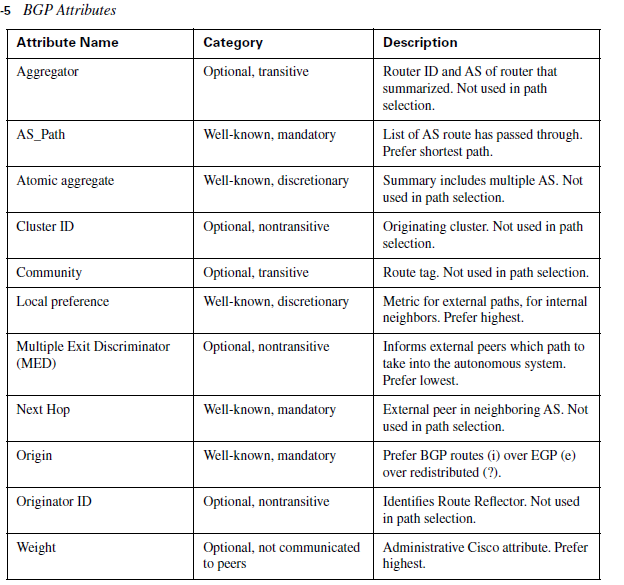
well known mandatory: everyone supports, must be in update message (next_hop, origin, as_path)
well known discretionary: everyone supports, might not be in update message (local pref, atomic aggregate)
Optional non-transitive: does not travel from router to router (Aggregator, MED)
Do not use or advertise a route learned via IBGP until the same route has been learned from the internal routing protocol.
-for IBGP peers: do not change next hop address on advertised routes.
-for EBGP peers: change next hop address on advertised routes.
When we create neighbor relation within IBGP or Ebgp between loopback addresses we need to use update source loopback
when we create neighbor relation between ebgp routers having loopback address we need to use ebgp multihop since loopback address sees itself sees as one hop away.
When only BGP is configured on IBGP, do no synchronization on all routers in AS and do clear and reset the process(clear ip bgp *)
Issue: since with IBGP, next hop is not changed, internal router will not be able to reach ebgp router so solution is to redistribute external ebgp route to routers in internal AS or another solution is to set next hop- self command in border router.
Weight is cisco propriety and its local to the router. It is set on per neighbor basis.
origin code: i iGP(entering with network command) or e EGP or? incomplete (redistribute routes into BGP)
bgp default local-preference 100. Mainly used when we want to pass routes through that particular router.
policy_routing : the programming language of routing table.